Duplicate content : a complete guideline
Article recap :
-
Duplicate content is a duplication originated from the “system”- this type of duplication is considered free from malicious intentions, while spun and copied texts are contents that were intentionally adapted and copied from other sites
-
Google and other search engines do not directly penalize pages with duplicate content, but they do for spun and copied texts
-
Some of the solutions to minimize the duplication of content are canonical URLs, HTTP 301 redirect, consistency of internal links, meta-robots, and Link to the original article (for guest posts)
Duplicate content: an ultimate definition
We can define duplicate content as any content that is possible to find on the internet in more than one place, that is, in more than one URL. According to Google Webmaster Guidelines (2020): “Duplicate content generally refers to substantive blocks of content within or across domains that either completely matches other content or are appreciably similar(...)”.
It is important to make the distinction between duplicate content, spun text, and copied text. Duplicate content is a duplication originated from the “system”- normally, this type of duplication is considered free from malicious intentions, while spun and copied texts are contents that were intentionally “adapted” or completely copied from other sites, thus, they are not treated in the same way. Here you have some reasons why duplication of content can arise :
-
Page repetition (eg. print version; optimized version, sale version)
-
Protocol overlap (eg. migration from HTTP to HTTPS)
-
Overlapping domain (eg. www and non-www)
-
Indexing of internal search URLs
-
Faceted navigation and parameterized URLs
-
Syndicated content (eg public RSS feed; Aggregators)
-
Press releases and Guest-posting; Attachment URL (PDF, images)
Duplicate content vs spun and copied content : are they penalized by search engines ?
Contrary to what most people may think, Google and other search engines do not penalize pages with duplicate content. What they do, indeed, is reward web pages with unique and added-value content, by displaying them in higher positions. Even if duplicate content does not imply a “real” penalty, it influences a web page rank and the loss of potential traffic - which end-result is the same. Why ? simply because when search engine crawlers identify duplicate content they are not able to figure out which is the one or which version they should include or exclude from their indices.
Therefore, if you do not tell Google or other search engines which content is the correct one to display, they will be in charge of choosing one of the versions - possibly opting for the version that was indexed first. Also, if many external links are directing to that version of the page, its chances of being chosen are even bigger. Besides choosing which content to display in search results, Google and other search engines also need you to determine which version will be considered the “authority” in the case of other sites linked to one of the versions of the content. Again, if you don't tell search engines which version will be the authority, they can assign it to the wrong version and even dilute the authority among the various versions - and, consequently, impairing the placement of content in search results. This directly affects your positioning and reduces the number of visitors that come to your page.
On the other hand, spun and copied content can be directly penalized by search engines. Although, the degree of the penalties will depend on the volume and frequency of adapted and copied content found on your website. If the majority of your web pages don’t have spun and copied content, the chances of only the page with spun and copied being penalized is pretty high. However, if the majority of your web pages are constituted by spun and copied content, you will risk having your entire website penalized and not being indexed at all.
How to minimize the duplication of content
1. Canonization of URLs
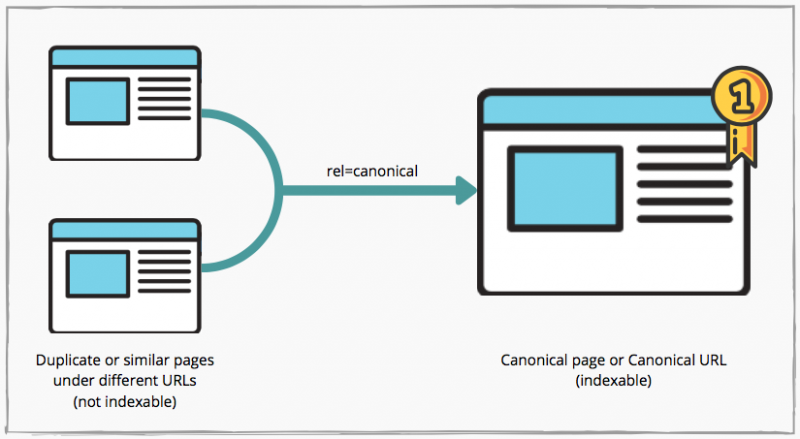
Launched in 2009 by Google, the HTML <link rel = “canonical”> tag consists of creating a static reference in HTML that points to the preferred version for indexing : the canonical URL. It is common to use the rel = “canonical” tag in a URL when you have other pages in which users will find similar or the same content.
For example, imagine that you have a page for the category “white sneakers” in your website and you create a sales page for the same white sneakers category. The content of both pages will be the same, only the prices will change. If you indicate which page you want search engines to index, that is, the canonical page*, they will only consider the one you’ve indicated.
(*) Mind the choice of your canonical page : if you indicate your sales page as the canonical one, you risk having it being displayed in the SERPs even after the end of your sales, and that may disappoint your customers. Except if it is part of your strategy, prioritize non-temporary pages as your canonical URL.
2. HTTP 301 redirect
Known as an instruction on the server that informs that Page A is now Page B so that when the visitor accesses page A, it will be automatically forwarded to the address of Page B.
This solution is generally applied when the same content is accessible from several URLs. This solution is commonly used in situations such as "www.shoes.com" vs "shoes.com" and "http://shoes.com/" vs "https://shoes.com/", for example. It is an effective method to prevent search engines from following a document that is not identified as canonical. They are therefore sent directly to the final document.
3. Consistency of internal links
Many pages can be searched for more than one link, for example, http://your_domain.com or http://www.your_domain.com. In order not to confuse Google, don't use links from different URLs on your site that lead to the same page.
4. Use meta-robots “noindex”
This tag allows search engines to crawl a page without including it in the search results. If you use the “noindex” tag in the HTML, Google will drop the page entirely and not display it in the SERPs, even if other sites link to it.
If you want your “noindex” directive to work effectively, you need to be sure that your page is not blocked by the robots.txt file. Because if it is the case, crawlers won’t be able to have access to your directives and will keep displaying in the SERPs.
 by ,
by ,  by ,
by ,