Duplicate content : le guide complet
Récapitulatif :
-
Le Duplicate content (ou la duplication de contenu) est une pratique tolérée en SEO. A l’inverse le plagiat ou le “copié-collé” sont considérés comme des contenus qui ont été intentionnellement adaptés et/ou copiés à partir d'autres sites.
-
Google et les autres moteurs de recherche ne pénalisent pas directement les pages dont le contenu est dupliqué. Le duplicate content peut néanmoins être punis lorsqu’un contenu est similaire à 100% à celui d’autres pages.
-
Quelques astuces existent pour échapper à la vigilance des moteurs de recherche sur le duplicate content : les URL canoniques, la redirection HTTP 301, la cohérence des liens internes, les meta robots et le lien vers l'article original.
Le Duplicate content : définition
On peut définir le duplicate content comme tout contenu qu'il est possible de retrouver sur plusieurs pages internet à divers endroits, c'est-à-dire à plusieurs URLs, ou au sein d’un même site web.
La définition selon Google Webmaster Guidelines (2020) est la suivante : “On entend par contenu dupliqué des blocs de contenu importants à l'intérieur d'un domaine, ou entre domaines, qui correspondent complètement à d'autres contenus, ou sont sensiblement similaires (...)".
Il est donc important de savoir faire la distinction entre le duplicate content, le plagiat et le copié-collé.
Le duplicate content est autorisé par le système. Il s’agit d’une pratique de "grey hat".
Le plagiat et le copié-collé sont des pratiques où il y a une intention délibérée de copier, ou de piquer, du contenu provenant d’autres sites web.
Voici quelques situation dans lesquelles il peut y avoir duplication de contenu :
-
La répétition de pages (ex : pages de promotion, page optimisée etc..)
-
Chevauchement des protocoles (par exemple, migration de HTTP à HTTPS) ;
-
Chevauchement de domaine (par exemple, www et non-www) ;
-
Indexation des URL de recherche interne ;
-
Navigation par facettes et URL paramétrées ;
-
Contenu syndiqué (par exemple, flux RSS public etc) ;
-
Communiqués de presse et affichage d'invités ; URL de pièces jointes (PDF, images)
Duplicate content, plagiat et copié-collé : sont-ils sanctionnés par les moteurs de recherche ?
Contrairement à ce que beaucoup de personnes pensent, le duplicate content n’est pas sanctionné par les moteurs de recherche.
En revanche, les moteurs de recherche “récompensent” davantage les pages possédant un contenu unique et à forte valeur ajoutée. C’est pourquoi, même si le duplicate content n’est pas directement sanctionné, celui-ci a une influence plutôt négative sur le classement d’une page web dans les SERPs. Ce qui a un impact sur le trafic potentiel d’un site.
En effet, les robots des moteurs de recherche identifient un contenu qui existe en double. Ils ne sont pas en mesure de déterminer quel est le contenu d’origine, ni quelle version ils doivent conserver ou supprimer pour l'indexation.
Par conséquent, leurs crawlers choisiront le contenu à afficher parmi l'une des “versions” disponibles, en optant le plus souvent pour celle qui a été indexée en premier.
De plus, si de nombreux backlinks renvoient à la page la mieux indexée, cela augmentera ses chances d'être privilégiée par les robots pour être la mieux référencée, parmi l’ensemble des pages concernées par le duplicate content.
Google et les autres moteurs de recherche ont également besoin que vous déterminiez quelle version sera considérée comme “la version prioritaire” : si vous n'indiquez pas aux moteurs de recherche quelle version sera prioritaire, ils peuvent l'attribuer à la mauvaise version et même diluer l'autorité parmi les différentes versions disponibles - et, par conséquent - nuire au placement du contenu dans les résultats de recherche. Cela affecte directement votre positionnement et réduit le nombre de visiteurs qui viennent sur votre page.
Le plagiat ou le "copié-collé" sont directement sanctionnés par les moteurs de recherche. L’importance des sanctions dépendra du volume de contenu copié sur un site web. Si la majorité de vos pages web n'ont pas de contenu copié-collé, les chances que seule la page avec le contenu copié-collé soit pénalisée sont assez élevées. Cependant, si la majorité des pages sont constituées de contenus plagiés, vous risquez de voir l'ensemble de votre site pénalisé et de ne pas être indexé dans les SERPs.
Comment minimiser la duplication de contenu
1. Indiquer l’URL canonique
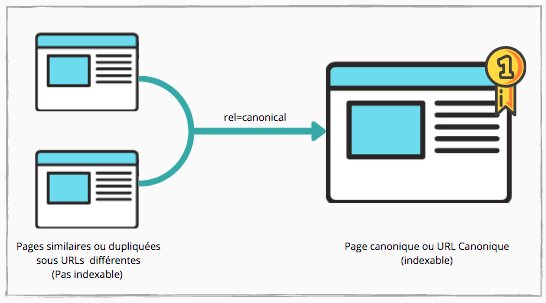
Lancée en 2009 par Google, la balise HTML <link rel = "canonical"> consiste à créer une référence qui pointe vers la version préférée (ou d'autorité) qu’on souhaite indexer : l'URL canonique. Il est donc courant d'utiliser la balise rel = "canonical" dans une URL lorsqu’on possède d'autres pages dans lesquelles on retrouve un contenu similaire ou identique.
Par exemple, votre site possède une page pour la catégorie "baskets blanches". Vous avez également dû créer une autre page promotion incluant la catégorie “baskets blanches”. Le contenu des deux pages sera forcément le même, seuls les prix seront différents.
Il faut donc indiquer aux moteurs de recherche quelle est la page qu’on souhaite indexer, c'est-à-dire indiquer celle qui aura l’url canonique*. Les moteurs de recherche se concentreront uniquement sur cette page pour l’indexation.
(*) Soyez vigilants sur le choix des URL canoniques ! En indiquant une page promotion d’un produit avec une URL canonique, vous risquez de la voir affichée en priorité dans les SERPs, même si la promotion n'est plus d'actualité. Evitez donc d’indiquer une URL canonique pour des pages ayant une durée de vie limitée ou ayant un caractère temporaire, sauf si cela fait partie de votre stratégie.
2. La redirection HTTP 301
Il s’agit d’une instruction adressée au serveur pour l’informer qu’une page "A" est devenue une nouvelle page "B". Ainsi, lorsqu’un visiteur accède à la page "A", il est automatiquement transféré à l'adresse de la nouvelle page "B" grâce à la redirection HTTP 301.
Cette solution est généralement appliquée lorsque qu'un même contenu est accessible depuis plusieurs URLs. Cette solution est courante dans les situations "www.chaussures.com" vs "chaussure.com" et "http://chaussure.com/" vs "https://chaussure.com/", par exemple. Il s’agit d’une méthode efficace pour que les moteurs de recherche ne suivent pas le document qui n'est pas identifié comme canonique. Ils sont donc directement envoyés vers le document final.
3. La cohérence des liens internes
De nombreuses pages peuvent être recherchées à partir de plusieurs liens, par exemple: "http://votre_domaine.com" ou "http://www.votre_domaine.com". Afin de ne pas perturber Google, il est recommandé de ne pas utiliser de liens provenant de différentes URLs de votre site et qui mènent à la même page.
4. L’instruction “noindex”
Il s’agit d’une instruction qui indique aux moteurs de recherche qu’ils peuvent explorer une page, mais sans l’indexer dans les résultats de la recherche. Si vous utilisez la balise "noindex" dans le code HTML d’une page, Google "l'abandonne" entièrement et ne l'affiche pas dans les SERPs, même si d'autres sites l’y renvoient.
Si vous voulez que votre directive "noindex" fonctionne efficacement, vous devez vous assurer que votre page n'est pas bloquée par le fichier robots.txt. , car les crawlers ne pourront pas avoir accès à votre directive et continueront à afficher la page dans les SERPs.
 by ,
by ,  by ,
by ,